|
How to Read Paintings: Semantic Art
Understanding with Multi-Modal Retrieval
Noa Garcia Docampo, George Vogiatzis.
ECCV Workshops, 2018
Automatic art analysis has been mostly focused on classifying
artworks into different artistic styles. However, understanding an
artistic representation involves more complex processes, such as identifying
the elements in the scene or recognizing author influences. Here. we
present SemArt, a multi-modal dataset for semantic art understanding.
SemArt is a collection of fine-art painting images in which each image is
associated to a number of attributes and a textual artistic comment, such
as those that appear in art catalogues or museum collections. To evaluate
semantic art understanding, we envisage the Text2Art challenge, a
multi-modal retrieval task where relevant paintings are retrieved according
to an artistic text, and vice versa. We also propose several models for
encoding visual and textual artistic representations into a common semantic
space. Our best approach is able to find the correct image within
the top 10 ranked images in the 45.5% of the test samples. Moreover,
our models show remarkable levels of art understanding when compared
against human evaluation. Project website containing code and dataset here, slides here.
|

|
|
Neural Caption Generation for News Images
Vishwash Batra, Yulan He, George Vogiatzis,
Language Resources and Evaluation Conference (LREC) 2018
Automatic caption generation of images has gained significant interest. It gives rise to a lot of interesting image-related applications. For example, it could help in image/video retrieval and management of vast amount of multimedia data available on the Internet. It could also help in development of tools that can aid visually impaired individuals in accessing multimedia content. In this paper, we particularly focus on news images and propose a methodology for automatically generating captions for news paper articles consisting of a text paragraph and an image. We propose several deep neural network architectures built upon Recurrent Neural Networks. Results on a BBC News dataset show that our proposed approach outperforms a traditional method based on Latent Dirichlet Allocation using both automatic evaluation based on BLEU scores and human evaluation.
|

|
|
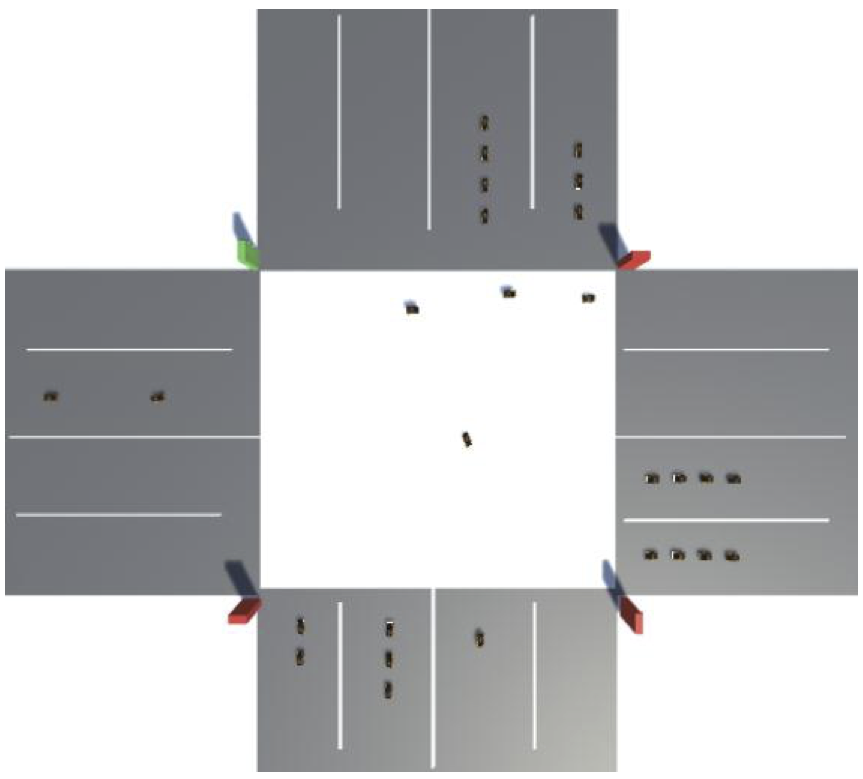
Deep Reinforcement Learning for Autonomous Traffic Light Control
Deepeka Garg, Maria Chli, George Vogiatzis,
IEEE International Conference on Intelligent Transportation Engineering (ICITE) 2018
In urban areas, the efficiency of traffic flows largely depends on signal operation and expansion of the existing signal infrastructure is not feasible due to spatial, economic and environmental constraints. In this paper, we address the problem of congestion around the road intersections. We developed our traffic simulator to optimally simulate various traffic scenarios, closely related to real-world traffic situations. We contend that adaptive real-time traffic optimization is the key to improving existing infrastructure's effectiveness by enabling the traffic control system to learn, adapt and evolve according to the environment it is exposed to. We put forward a vision-based, deep reinforcement learning approach based on ConvNets and Policy Gradients to configure traffic light control policies. The algorithm is fed real-time traffic information and aims to optimize the flows of vehicles travelling through road intersections. Our preliminary test results demonstrate that, as compared to the traffic light control methodologies based on previously proposed models, configuration of traffic light policies through this novel method is extremely beneficial.
|
|
|
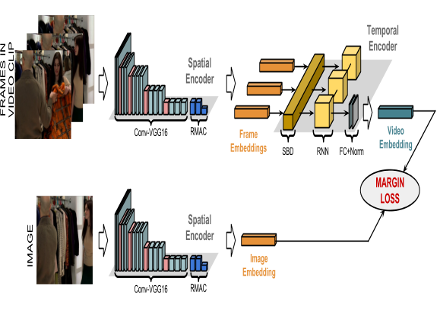
Asymmetric Spatio-Temporal Embeddings for Large-Scale Image-to-Video Retrieval
Noa Garcia Docampo, George Vogiatzis.
BMVC 2018
Here we are revisiting our image-to-video shot retrieval work, this time employing a recurrent network (GRU or LSTM). Instead of using expensive feature tracking to exploit the temporal redundancies of a video shot, we use the recurrent network to learn how to best summarize a shot into a vector. The network is fed a sequence of RMAC feature vectors from each frame in the shot, and produces a vector output at the end. Another network maps photos taken off the video screne onto frame vectors that live in the same semantic space as the shot summary vectors. We train both networks using a margin loss, that ensures that shot summary vectors match frame vectors from the same shot, while not matching frame vectors from different shots. We find significant improvements over state-of-the-art in standard image-to-vide datasets.
|
|
|
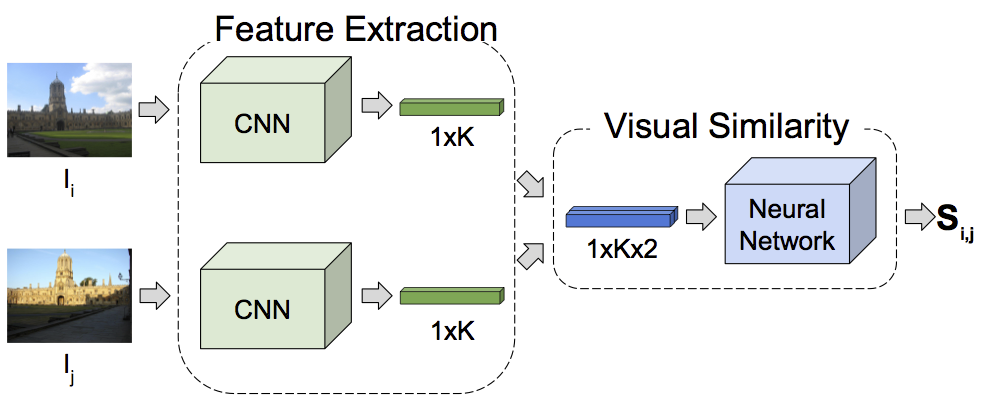
Learning Image Similarity
Noa Garcia Docampo, George Vogiatzis.
(to appear),Feb 2019
The estimation of visual similarity is at the cornerstone of much of Computer Vision. However most work on the field assumes a two stage approach: convert each of the two images into vectors and then compute some distance metric on the vectors (e.g. cosine similarity). However this imposes a metric structure which may not agree with our intuitive understanding. E.g. an image of a horse is visually similar to a centaur, which is visually similar to a human. However the horse is not similar to the human, thus violating the triangle inequality. In this work we explore training a network on the concept of visual similarity and show improvements over state-of-the-art image matching algorithms. Preprint here.
|
|
|
Dress like a Star: Retrieving Fashion Products from Videos
Noa Garcia Docampo, George Vogiatzis.
In European Conference on Computer Vision Workshops (ECCVW) 2018
Exploiting Redundancy in Binary Features for Image Retrieval in Large-Scale Video Collections
Noa Garcia Docampo, George Vogiatzis.
In European Conference on Visual Media Production (CVMP) 2016
In this project we look at the problem of identifying a scene out of a very large video collection from a single photo, known as image-to-video retrieval. The main application involves using a mobile phone to grab a picture of a video presentation (e.g. a cinema screen) and retrieving interesting information about the scene shown, e.g. items of commercial interest or educational information. We solve the problem by exploiting spatio-temporal redundancies in video, as well as a novel KD-tree based search engine. In our experiments consisting of 40 full feature-length films, we are able to maintain the accuracy of linear brute-force search (around 90%) while reducing memory requirements by a factor of 42.
|

|
|
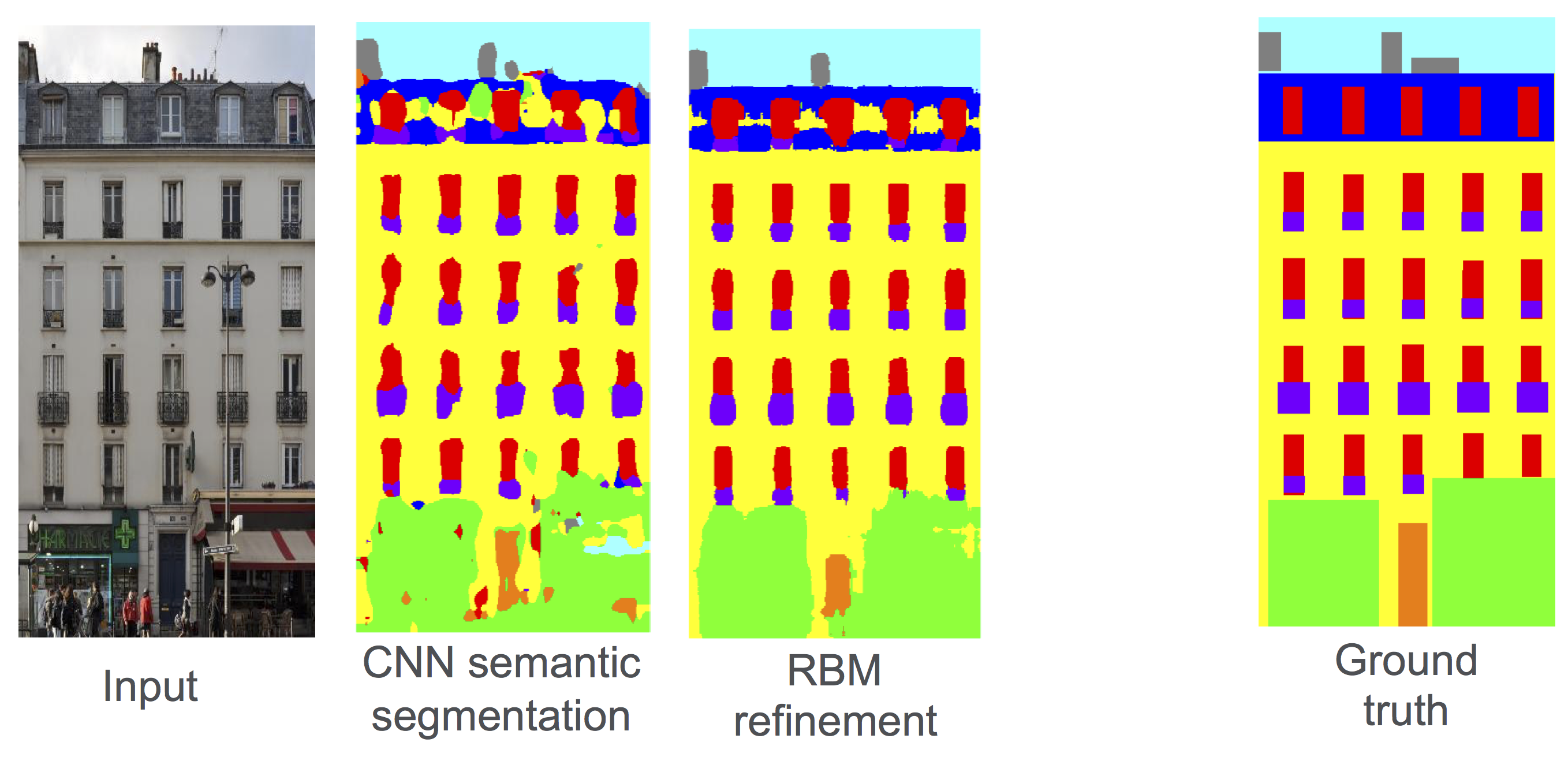
A Deep Learning Pipeline for Semantic Facade Segmentation
Radwa Fathalla, George Vogiatzis.
BMVC, 2017
In this work we turn our attention to semantic scene interpretation in domains where strong priors exist. Architecture is
a prime example of that domain where strict stylistic rules can be used to enhance a pure appearance-based reconstruction.
Our approach integrates appearance and layout cues in a single framework. The most likely label based on appearance is obtained
through applying state-of-the-art per-pixel segmentation ConvNets. This is further optimized through Restricted
Boltzmann Machines (RBM), that have been trained to reproduce the architectural patterns observed in a large data collection
(e.g. symmetry, repetition etc) Experimentally,we are on par with the reported performance results. However, we do not
explicitly specify any hand-engineered features that are architectural scene dependent, nor do we include any
dataset specific heuristics/thresholds.
|
|
|
Multi-model fitting based on Minimum
Spanning Tree
Radwa Fathalla, George Vogiatzis.
BMVC, 2014
In this work we are looking at multi-model fitting of geometrical structures. Our approach is based on
gestalt principles of similarity and proximity which are realized using Mininum Spanning Trees and Spectral Clustering
respecively. The algorithm can be generalised to various settings without changing the input parameters. We demonstrate
improvements compared to state-of-the-art in plane, homography and motion segmentation examples.
|

|
|
Large Scale Multi-view Stereopsis Evaluation
Rasmus Jensen, Anders Dahl, George Vogiatzis, Engin Tola, Henrik Aanaes.
In Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR),June 2014
The Middlebury evaluation for multi-view stereo has been really successful in motivating researchers, inspiring numerous publications and driving the field of MVS forward.
In this work, eight years after the publication of the Middlebury dataset, we are releasing a large scale, realistic and very challenging new dataset.
The data has been captured using DTU's robotic arm apparatus and ground truth is obtained using a structured light scanner.
The data acquisition is very accurate (0.1pixels reprojection error and 0.2mm in geometric accuracy) and covers a very wide range of scenes including well-textured, partially untextured, diffuse, shiny and metalic objects.
As a first benchmark, we evaluated three established state-of-the-art MVS methods from the top performers at Middlebury.
The main finding was that all methods perform to a very high standard, illustrating how much the technology has progressed.
However there were also serious performance limitations, mainly to do with challenging scenes.
This will hopefully inspire a second round of improvements until the technology is finally ready for real-world use.
The project has its own website that can be found here. Also, check out a video showing the acquisition setup.
|

|
|
A Generative Model for Online Depth Fusion
O. Woodford and G. Vogiatzis.
In proceedings of European Conference of Computer Vision (ECCV) LNCS Vol 7576, 2012, pp 144-157
In this project we looked at the problem of fusing depth-map measurements probabilistically. The results show our method outperforming competitors in some regimes, especially under heavy noise/outlier measurements.
However the key merit of the approach is the principled variational Bayesian framework which shows great promise and paves the way for more complex models. More on this soon!
The paper describes a probabilistic, online, depth map fusion frame-work, whose generative model for the sensor measurement process accurately incorporates both long-range visibility constraints and a spatially varying, probabilistic outlier model. In addition, we propose an inference algorithm that updates the state variables of this model in linear time each frame. Our detailed evaluation compares our approach against several others, demonstrating and explaining the improvements that this model offers as well as highlighting a problem with all current methods: systemic bias.
Check out the supplementary video showing the system in action here
|

|
|
Video-based, Real-Time Multi View Stereo
G. Vogiatzis and C. Hernández.
In Image and Vision Computing, 29(7):434-441, 2011.
We investigate the problem of obtaining a dense reconstruction in real-time, from a live video stream. In recent years, Multi-view stereo (MVS) has received considerable attention and a number of methods have been proposed. However, most methods operate under the assumption of a relatively sparse set of still images as input and unlimited computation time. Video based MVS has received less attention despite the fact that video sequences offer significant benefits in terms of usability of MVS systems. In this paper we propose a novel video based MVS algorithm that is suitable for real-time, interactive 3d modeling with a hand-held camera. The key idea is a per-pixel, probabilistic depth estimation scheme that updates posterior depth distributions with every new frame. The current implementation is capable of updating 15 million distributions per second. We evaluate the proposed method against the state-of-the-art real-time MVS method and show improvement in terms of accuracy.
Check out some videos of the system in action here
The supplementary material containing some derivations and the update formulae can be found here.
|
|
|
Automatic Object Segmentation from Calibrated Images
N. D. F. Cambell, G. Vogiatzis, C. Hernández and R. Cipolla.
In Proceedings 8th European Conference on Visual Media Production,(CVMP), 2011
This paper addresses the problem of automatically obtaining
the object/background segmentation of a rigid 3D object
observed in a set of images that have been calibrated for
camera pose and intrinsics. Such segmentations can be used
to obtain a shape representation of a potentially texture-less
object by computing a visual hull. We propose an automatic
approach where the object to be segmented is identified by the
pose of the cameras instead of user input such as 2D bounding
rectangles or brush-strokes.
The key behind our method is a pairwise MRF framework that
combines (a) foreground/background appearance models, (b)
epipolar constraints and (c) weak stereo correspondence into a
single segmentation cost function that can be efficiently solved
by Graph-cuts. The segmentation thus obtained is further
improved using silhouette coherency and then used to update
the foreground/background appearance models which are fed
into the next Graph-cut computation. These two steps are
iterated until segmentation convergences.
Our method can automatically provide a 3D surface
representation even in texture-less scenes where MVS
methods might fail. Furthermore, it confers improved
performance in images where the object is not readily
separable from the background in colour space, an area that
previous segmentation approaches have found challenging.
Paper was awarded the BBC Best Paper Prize!
|

|
|
Self-calibrated, multi-spectral photometric stereo for 3d face capture
G. Vogiatzis and C. Hernández.
In International Journal of Computer Vision, 97(1):91-103, 2012
This paper addresses the problem of obtaining 3d detailed
reconstructions of human faces in real-time and with
inexpensive hardware. We present an algorithm based on
a monocular multi-spectral photometric-stereo setup. This
system is known to capture high-detailed deforming 3d surfaces
at high frame rates and without having to use any
expensive hardware or synchronized light stage. However,
the main challenge of such a setup is the calibration stage,
which depends on the lights setup and how they interact
with the specific material being captured, in this case, human
faces. For this purpose we develop a self-calibration
technique where the person being captured is asked to perform
a rigid motion in front of the camera, maintaining a
neutral expression. Rigidity constrains are then used to
compute the head.s motion with a structure-from-motion algorithm.
Once the motion is obtained, a multi-view stereo
algorithm reconstructs a coarse 3d model of the face. This
coarse model is then used to estimate the lighting parameters
with a robust estimator which allows for detailed realtime
3d capture of faces. The calibration procedure is validated
with two real sequences.
The previous 3DPVT'10 version can be found here The capture system is identical to the one we presented
in ECCV'08.
The main difference is the clever calibration method for
photometric stereo that was inspired from our earlier
CVPR'06 work.
Check out the supplementary video
here
|

|
|
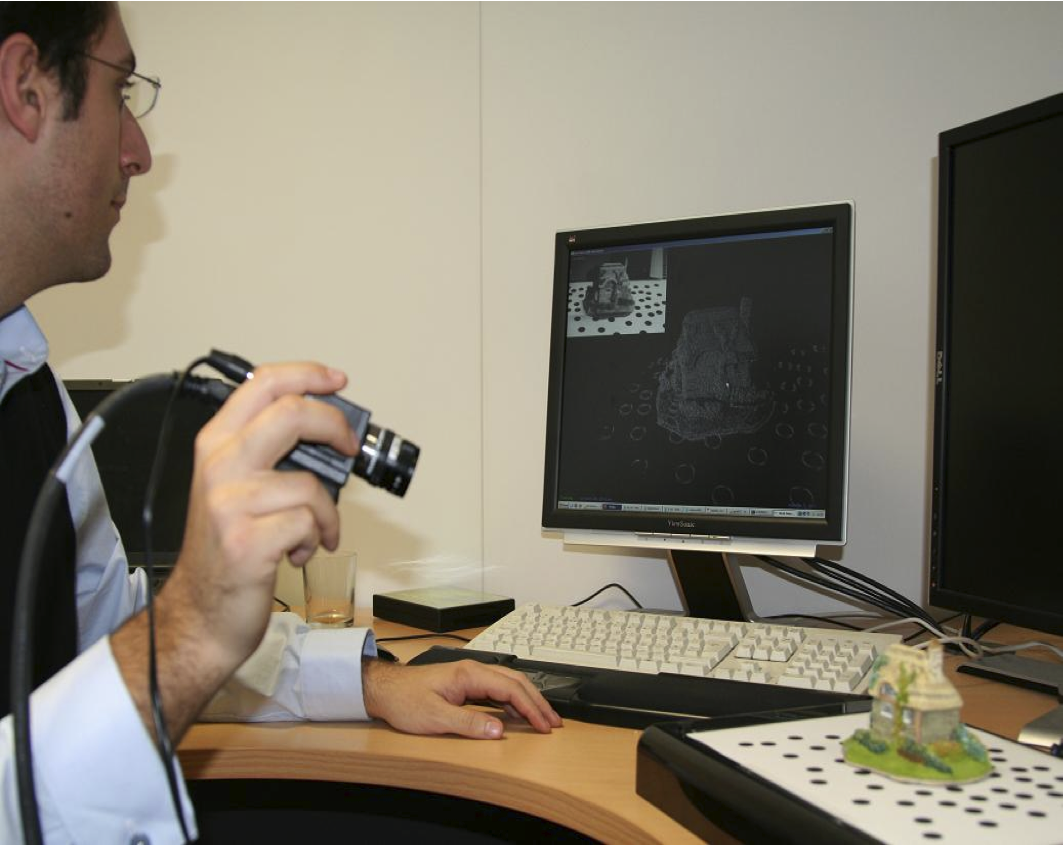
Using Multiple Hypotheses to Improve Depth-Maps for Multi-View Stereo
N. Campbell, G. Vogiatzis, C. Hernández and R. Cipolla.
In Proceedings European Conference of Computer Vision (ECCV), 2008.
This paper proposes an improvement to a large class of Multi-View Stereo algorithms that fuse stereo depth maps. We show that if individual depth-maps are filtered for outliers prior to the fusion stage, good performance can be maintained in sparse data-sets. Our strategy is to collect a list of good hypotheses for the depth of each pixel. We then chose the optimal depth for each pixel by enforcing consistency between neighbouring pixels in a depth-map. A crucial element of the fitering stage is the introduction of a possible unknown depth hypothesis for each pixel, which is selected by the algorithm when no consistent depth can be chosen. This pre-processing of the depth-maps allows the global fusion stage to operate on fewer outliers and consequently improve the performance under sparsity of data.
|
|
|
Shadows in Three-Source Photometric Stereo
C. Hernández, G. Vogiatzis and R. Cipolla.
In Proceedings European Conference of Computer Vision (ECCV), 2008.
Shadows present a significant challenge for Photometric Stereo methods. When four or more images are available, local surface orientation is overdetermined and the shadowed pixels can be discarded. In this paper we look at the challenging case when only three images under three different illuminations are available. In this case, when one of the three pixel intensity constraints is missing due to shadow, a 1 dof ambiguity per pixel arises. We show that using integrability one can resolve this ambiguity and use the remaining two constraints to reconstruct the geometry in the shadow regions. As the problem becomes ill-posed in the presence of noise, we describe a regularization scheme that improves the numerical performance of the algorithm while preserving data.
|
|
|
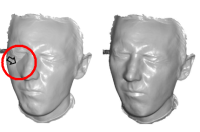
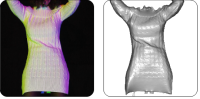
Non-rigid Photometric Stereo with Colored Lights
C. Hernández, G. Vogiatzis, G. Brostow, B. Stenger and R. Cipolla.
In Proceedings IEEE International Conference of Computer Vision (ICCV), 2007.
When three lights illuminate a surface from three different angles and with three different colors, there is a one-to-one mapping between the RGB color measured by a camera and the surface orientation. If we illuminate a complex object under this setup, we can invert the mapping to get surface orientations from an RGB image, then integrate those to get a depth-map. In this paper, this idea, previously used only with static objects, is applied to the reconstruction of a deforming object, such as a moving cloth. We capture color videos of complex motions of fabrics, from which we extract sequences of depth maps. We propose a simple scheme with which these depth maps can be registered to a canonical pose and this allows complex applications such as texture mapping or avatar skinning. A video showing the system in action can be found in the following links: short avi, longer version and from YouTube part 1 and part 2.
|
|
|
Multi-view Photometric Stereo
C. Hernández, G. Vogiatzis and R. Cipolla.
To appear in IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2008.
This is an extension and consolidation of our CVPR 2006 work on multi-view photometric stereo. The main difference of this paper is that significant albedo variations in the surface of the reconstructed object can be tolerated. In the case where albedo variation is present on the object, we can usually obtain reconstructions with classic multi-view dense stereo. We show however, how our work produces results of much higher geometric detail than multi-view stereo, by exploiting the change in illumination. An earlier version of this work appeared in
Lighting-up geometry:
accurate 3D modelling of museum artifacts with a torch and a camera
G. Vogiatzis, C. Hernández and R. Cipolla.
In Eurographics 2006, Short papers,
pages 85-88, 2006.
(talk)
|


|
|
Automatic 3D Object Segmentation in Multiple
Views using Volumetric Graph-Cuts
N. Campbell, G. Vogiatzis, C. Hernandez and R. Cipolla.
In Proceedings 18th British Machine Vision Conference (BMVC), 2007
vol. 1, pages 530-539, 2007.
(talk)
Many multi-view stereo methods are faced with the problem of segmenting 20-100 calibrated images of a 3D object. These segmentations are used to create a visual hull which is a first approximation to the object's geometry. In this paper we propose a simple technique for automatically segmenting these images. Our idea is based on two observations: (1) In each image the camera will usually fixate on the object of interest and (2) the segmentations are not independent because of the silhouette coherence constraint. We use (1) to initalise an object color model. We then perform a series of simultaneous segmentations using (2). In each iteration we update the color model based on previous results. The process converges to the correct segmentations after just a few iterations.
|

|
|
Multi-view Stereo via Volumetric Graph-cuts
and Occlusion Robust Photo-Consistency
G. Vogiatzis, C. Hernández, P. H. S. Torr, and R. Cipolla. IEEE Transactions in Pattern Analysis and Machine Intelligence (PAMI), vol. 29, no. 12, pages 2241-2246, Dec., 2007.
Here we revisit our CVPR 2005 work and develop a much improved formulation. The object surface is defined as a partition of 3D space into 'inside' and 'outside' regions. The cost functional, which we optimise using Graph-cuts, is a combination of a simple balooning force and an occlusion-independent Normalised Cross Correlation cost. The advantages of our approach are the following: (1) Objects of arbitrary topology can be fully represented and computed as a single surface
with no self-intersections.
(2) The representation and geometric regularisation is image and viewpoint independent.
(3) Global optimisation is computationally tractable, using existing max-flow algorithms.
|

|
|
Probabilistic visibility for multi-view stereo
C. Hernández, G. Vogiatzis and R. Cipolla.
In Proceedings IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2007.
In this work we explore how the photo-consistency criterion can be used to obtain a likelihood for a given 3D location being 'empty'. We observe that if a 3D point is considered as photo-consistent from a certain camera, then all 3D locations between that point and the camera are likely to be empty. In fact the degree of likelihood for 'emptiness' is related to the degree of photo-consistency. We formalise this observation probabilistically and show how it can be used to reconstruct difficult concavities in objects.
|

|
|
Reconstruction in
the Round Using Photometric Normals and Silhouettes
G. Vogiatzis, C. Hernández and R. Cipolla.
In Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
pages 1847-1854, 2006.
In this work we have obtained
full 3D reconstructions of single-albedo, near-Lambertian objects such as white porcelain
from 36 views under changing but unknown lighting (single distant light-source assumed). This work is
the first to generalise uncalibrated photometric stereo in the multi-view setting. For a more detailed
look at some other models we reconstructed using this technique, look
here.
All you will need is a java enabled browser.
|


|
|
Using Frontier
Points to Recover Shape, Reflectance and Illumination
G. Vogiatzis, P. Favaro and R. Cipolla.
In Proceedings IEEE International Conference of Computer Vision (ICCV),
pages 228-235, 2005.
Frontier Points are a robust geometrical
feature extracted from the silhouettes. They are points on the surface of the
object with a known 3D location and known local surface orientation. In this paper we have
shown how they can be used to recover information about the surface
reflectance of the object as well as illumination.
|
 |
|
Multi-view
stereo via Volumetric Graph-cuts
G. Vogiatzis, P.H.S. Torr and R. Cipolla.
In Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR),
pages 391-398, 2005.
(talk)
The object surface is defined as a boundary separating
the Visual Hull surface from an inner surface at a constant offset from and
inside the Visual Hull. The volume between these two surfaces is discretized
into voxels and for each voxel we compute a photo-consistency cost. Using Graph-Cuts
and a specially defined weighted graph, we compute the surface that optimally
separates voxels inside and outside the scene.
|

|
|
Reconstructing
Relief Surfaces
G. Vogiatzis, P.H.S. Torr, S. Seitz and R. Cipolla
In Proceedings 15th British Machine Vision Conference (BMVC),
pages 117-126, 2004.
(talk)
The object surface is defined as a height field on
top of a coarse approximation of the scene surface (typically the visual
hull). The height field is formulated as a Markov Random Field incorporating
photo-consistency and surface smoothness constraints. The resulting cost
function is optimized using Loopy Belief Propagation.
|


|
