Current
Reinforcement Learning for Traffic Signal Control
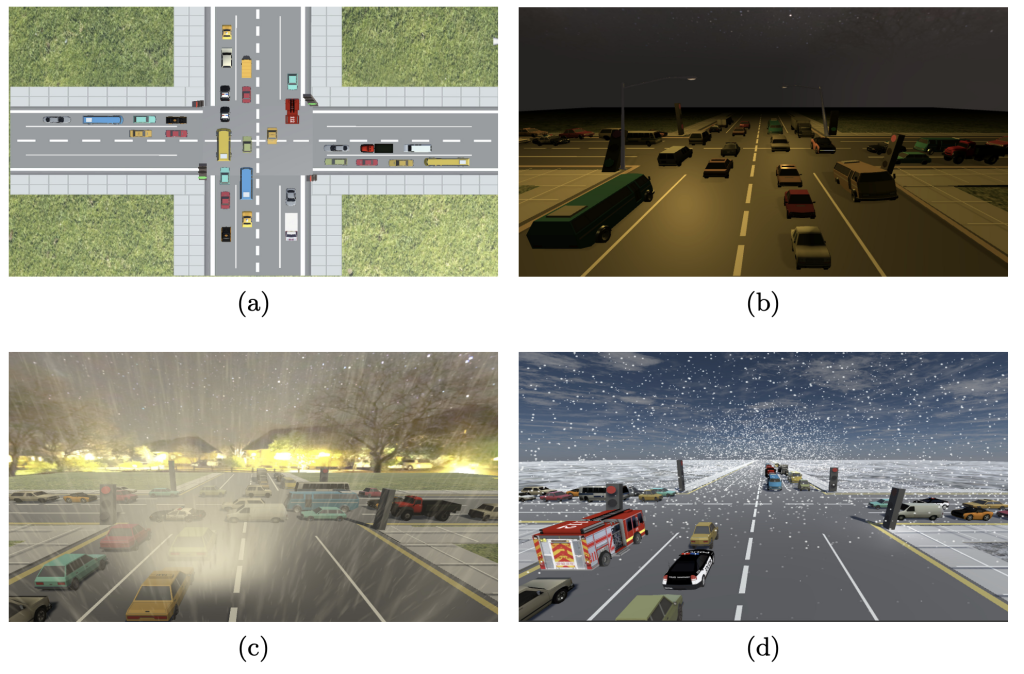
Deep and multi-agent reinforcement learning for intelligent traffic signal control, trained in rich 3D simulation and transferred to real-world networks.


Researcher in Computer Science, Loughborough University
I work in computer vision and deep learning — including 3D reconstruction, self-supervised monocular depth estimation, reinforcement learning for intelligent transport, and vision and language. Browse my research under Projects, find my papers under Publications, read more About my background, or get in touch via Contact.
Deep and multi-agent reinforcement learning for intelligent traffic signal control, trained in rich 3D simulation and transferred to real-world networks.

Learning to predict depth from single images without ground-truth supervision, with a focus on dynamic scenes and challenging conditions.

Recovering accurate 3D shape from collections of images, using multi-view stereo, volumetric graph-cuts, and probabilistic depth-map fusion.